Symmetrical Visual Contrastive Optimization:
Aligning Vision-Language Models with Minimal Contrastive Images

Large Vision-Language Models (VLMs) often over-rely on language priors and neglect visual details, leading to visual hallucinations. An example below illustrates a counterintuitive pattern, where a base-VLMLV-INT is most likely to generate the response about "the dog" when given no image input, and least likely when shown the matching image -- even less than with the mismatched image ("the cat").

We propose S-VCO (Symmetrical Visual Contrastive Optimization), a novel VLM finetuning paradigm that enforces explicit supervision over visual details and their alignment to texts, thus enhancing visually dependent task capabilities while preserving or improving general performance.
Using contrastive image-text pairs of detailed visual differences (visual counterfactual data), S-VCO enforces a strict visual focus by optimizing two key behaviors with no image input as an intermediate reference: Attending to the matching image & Rejecting the contradictory image.
Unlike "preference"-based finetuningDPO,mDPO,MFPO, S-VCO treats both sides of an image pair simply as contrastive conditions, where either can be "preferred" depending on the paired textual response. Through a symmetrical construct that flips roles (i.e., the "negative" image becomes the "preferred" visual condition when paired with the corresponding text), S-VCO fosters genuine alignment of image-text pairs without risking shortcut learning on superficial unimodal features.
Below are qualitative examples from various benchmarks, where S-VCO leads to significant enhancements of VLM's key vision-centric capabilities.

Compared to base-VLMsLV-INT,LV-1.5 and prior preference-tuning methodsDPO,mDPO, S-VCO demonstrates:
• enhanced ability to detect fine-grained visual details:
e.g., identifying the absence of a toothbrush.
• strong resilience to visual hallucinations:
e.g., recognizing marker-drawings instead of glasses, fire hydrants, slide-phones.
• advanced reasoning grounded in visual cues:
e.g., interpreting drive-lane conditions & regulations, estimating object sizes & distances.
• complex scene understanding by capturing intricate context details:
e.g., identifying outdoor weather through indoor windows, recognizing oncoming vehicles in low-light settings.
To complement the S-VCO objective, we construct MVC, a dataset of image pairs featuring Minimal but meaningful Visual Contrasts, paired with corresponding texts.
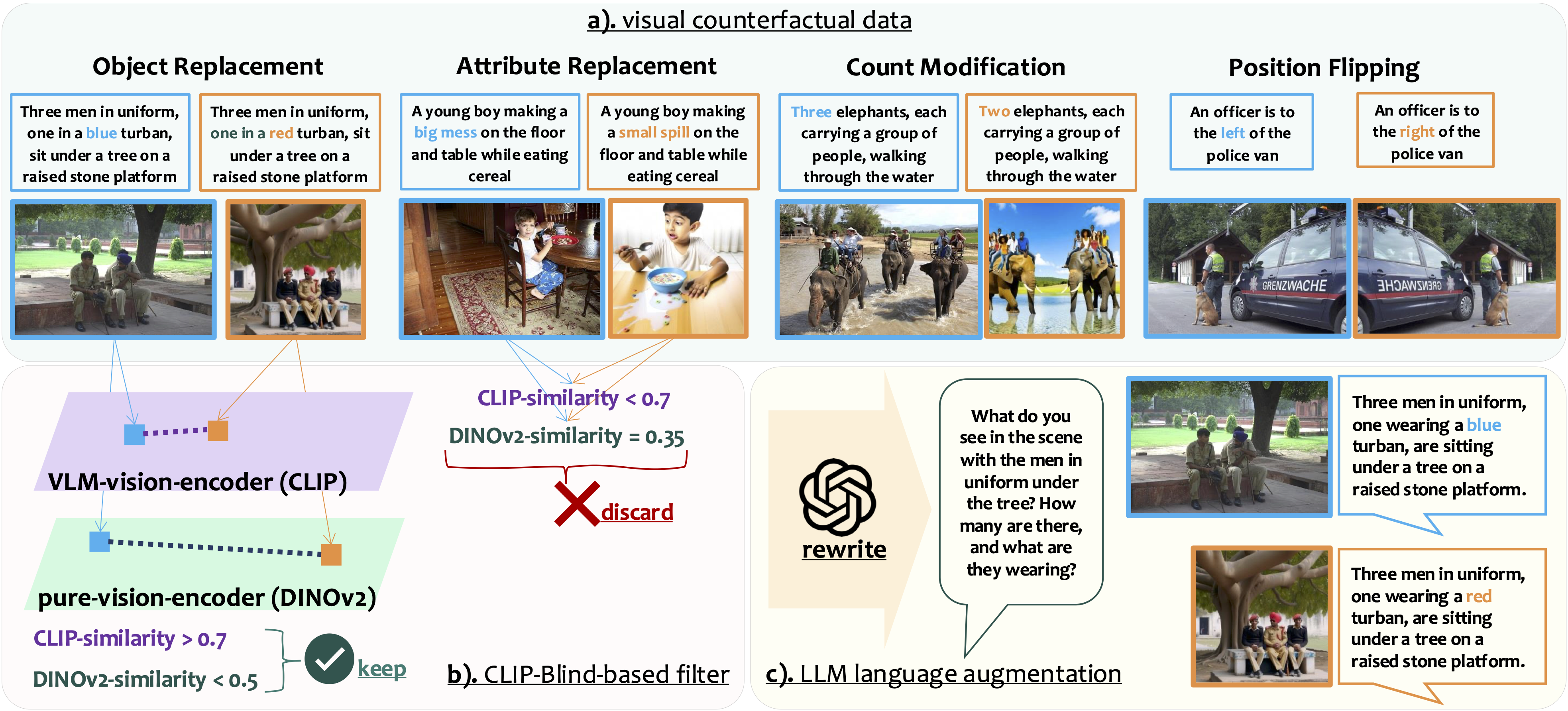
MVC builds upon visual counterfactual data sourcesCounterCurate,FineCops-Ref and implements:
• a vision-centric filterinspired by CLIP-Blindness to ensure the image pairs are visually challenging yet semantically relevant.
• a language-augmentation step that yields diversified wording in conversational-style, better suited for VLM finetuning.
We compared S-VCO with existing finetuning methodsDPO,mDPO, as well as our MVC dataset against prior preference tuning dataVLF on multiple base VLMsLV-1.5-7B, LV-INT-7B across diverse benchmarks covering various ability domains.
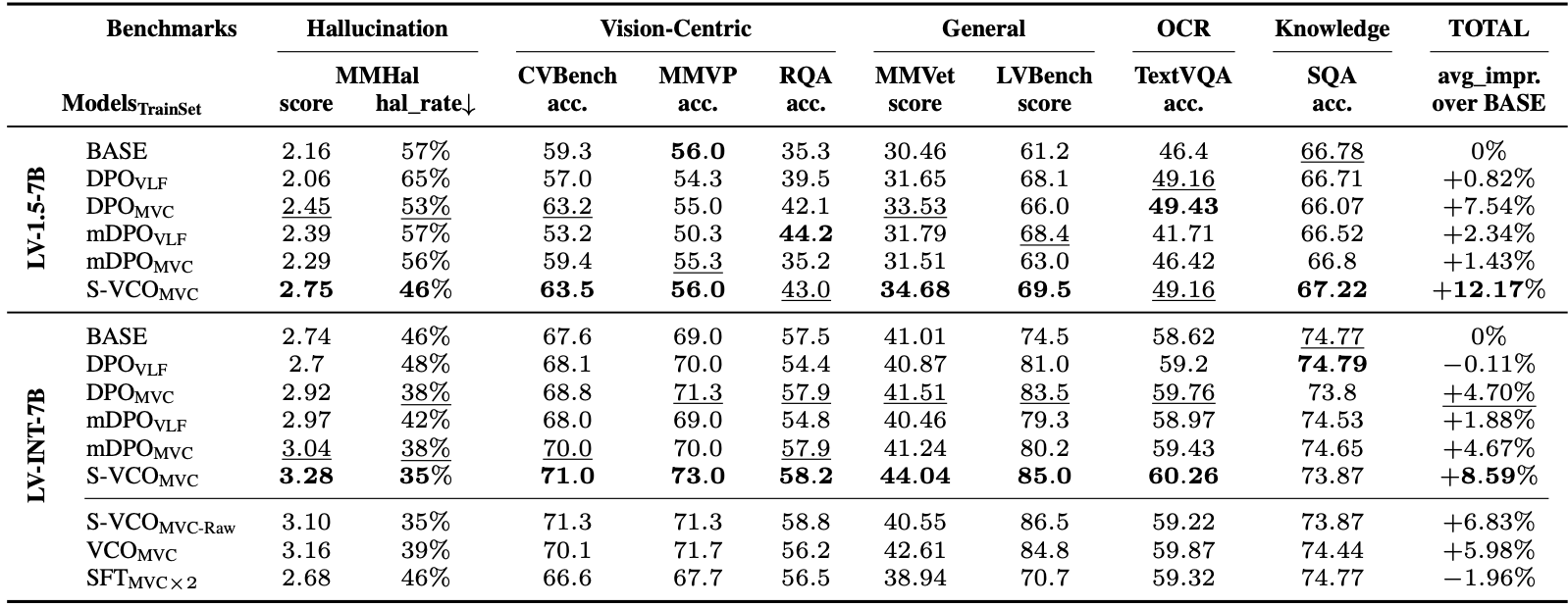
• S-VCO achieves consistently superior performance across benchmarks in various domains, improving LV-1.5 and LV-INT overall by 14.26% and 10.47%, respectively.
• S-VCO delivers the most substantial gains on visually demanding benchmarks e.g., MM-Hal & MMVP (> 20% improvement), MMVet, LLaVABench.
• MVC dataset enhances prior preference tuning methods: For LV-INT, both DPO and mDPO achieve greater overall improvements when trained on MVC; For LV-1.5, DPOMVC outperforms DPOVLF by ∼9% on average across benchmarks.
• Ablations (the last three rows) highlight the importance of MVC's data filtering & augmentation steps, S-VCO's symmetry construct, as well as the drawbacks of standard SFT even on doubled data size.
@misc{wu2025symmetricalvisualcontrastiveoptimization,
title={Symmetrical Visual Contrastive Optimization: Aligning Vision-Language Models with Minimal Contrastive Images},
author={Shengguang Wu and Fan-Yun Sun and Kaiyue Wen and Nick Haber},
year={2025},
eprint={2502.13928},
archivePrefix={arXiv},
primaryClass={cs.CV},
url={https://arxiv.org/abs/2502.13928},
}